MicroOps
具有很多功能的一个智能运维平台 点击去看看
Show
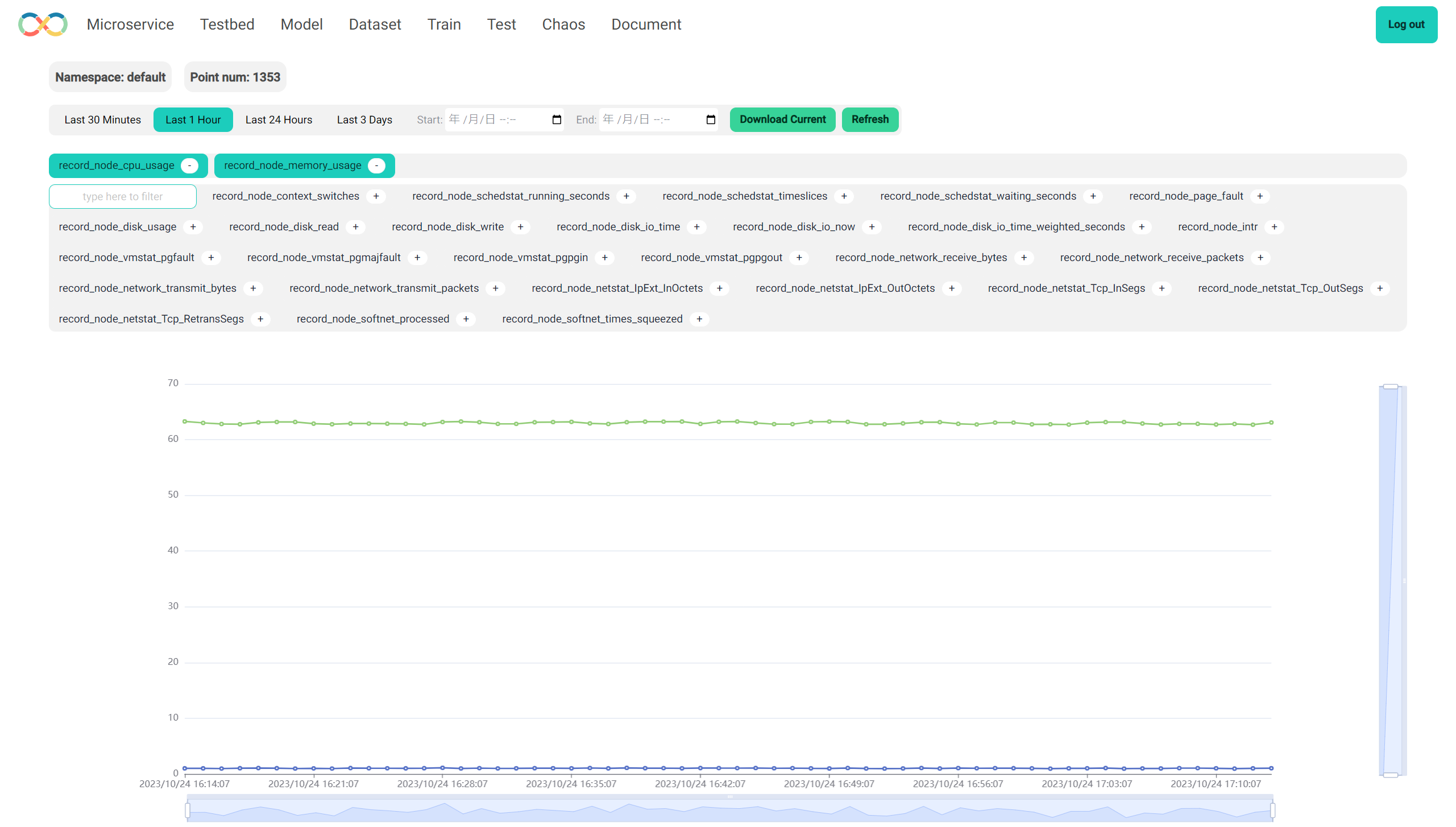
数据预览
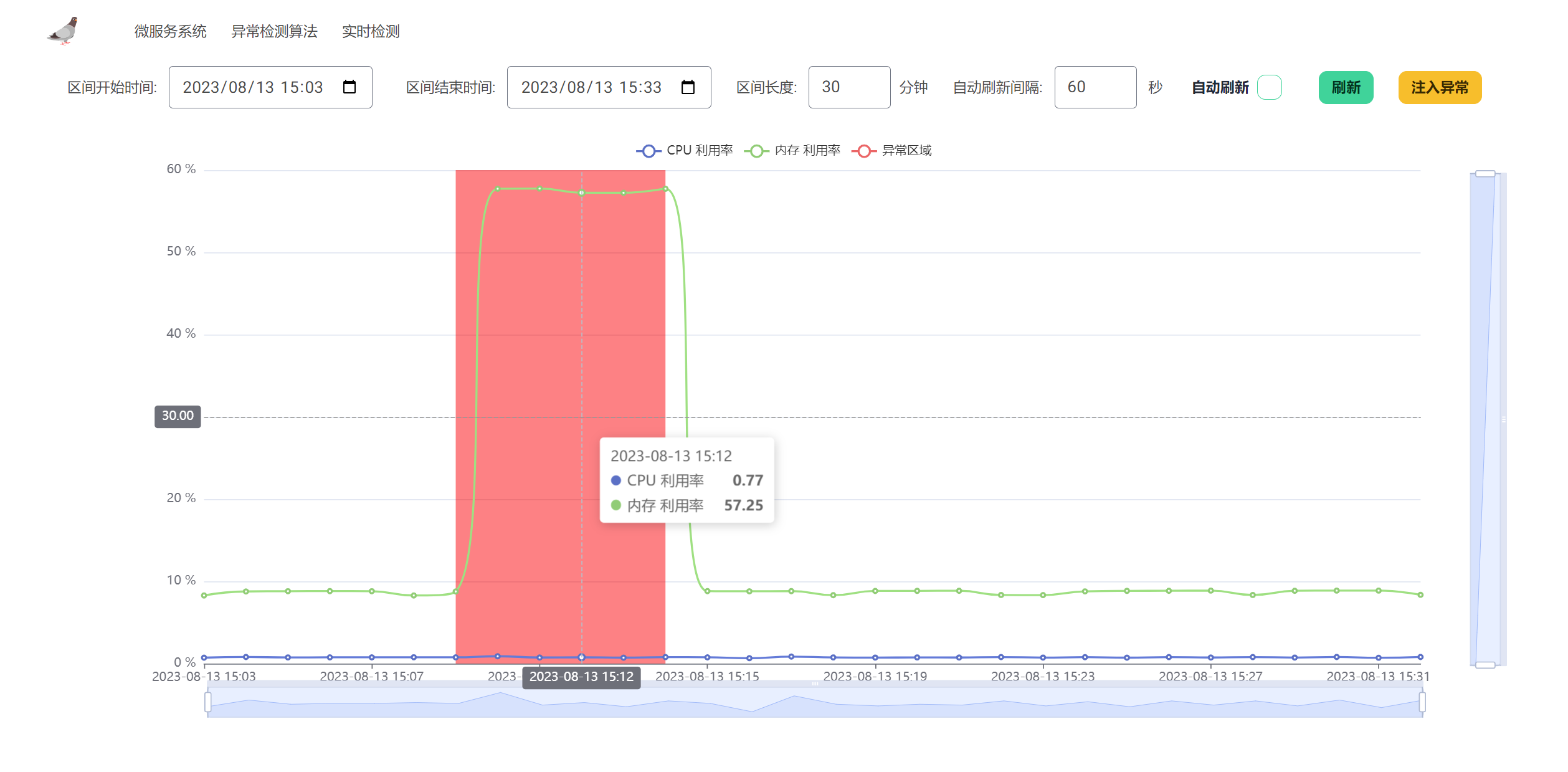
实时异常检测
架构
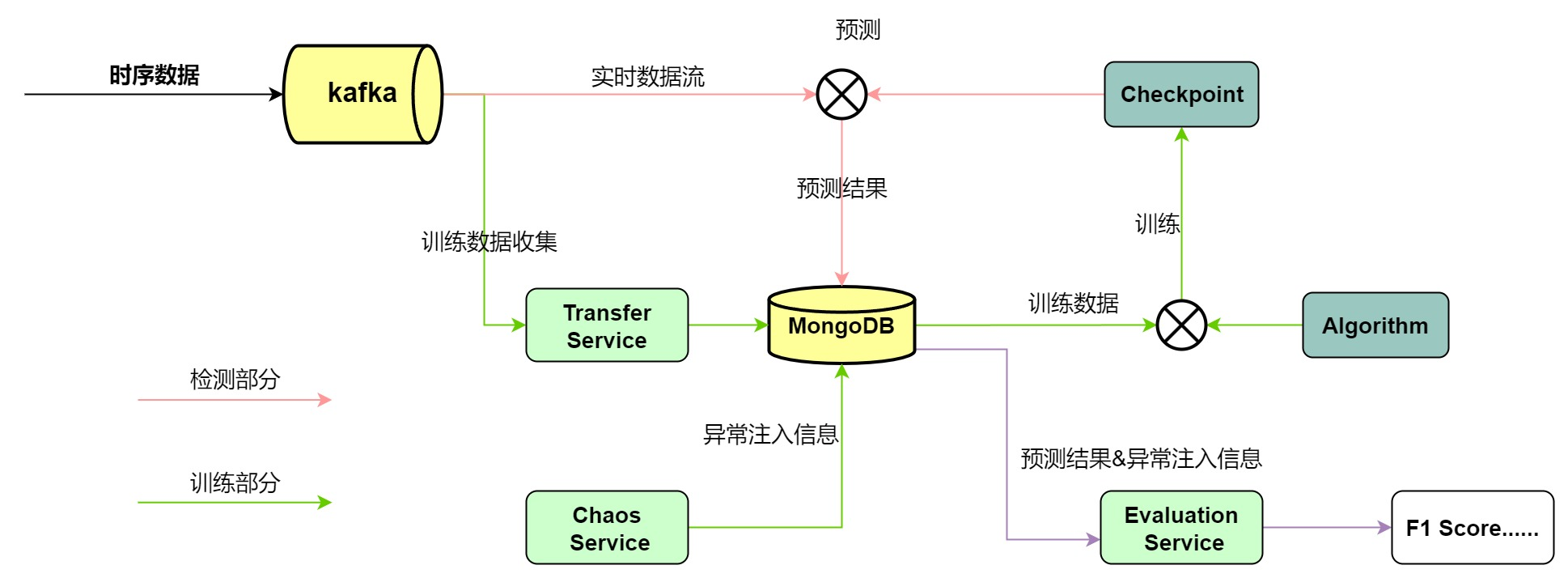
有两个比较关键的组件:Kafka和MongoDB。
Kafka 和的监控系统对接,各种 Metric、日志、Trace 信息都会被推送到Kafka中,由各种消费者进行消费;我们开发了一些服务,用来将各种观测信息写入 Kafka
- 定制版的 Jaeger – 支持将 Trace 解析后写入 MongoDB
- KafkaWriter – 对接 Prometheus 的 RemoteWrite 功能,结合 K8S 的元信息,给 Metric 打上更多的标签方便使用
- 一系列的收集服务
MongoDB是平台的核心,各种信息都会存储在MongoDB中
- 算法的元信息
- Benchmark 信息
- TestBed 信息
- 数据集和 Kafka Topic 信息
- 检测任务信息
- 训练任务信息
- 用户信息
- 异常注入记录
- 数据集
整体分为两大部分:训练和检测。
- 训练之前,需要根据 SDK 完成算法的开发,同时,来自
Kafka的数据也会被存储到MongoDB中,以备将来的训练。 - 训练时,选择算法和数据,在平台上提交一个任务即可。
- 训练后,会得到一个
checkpoint,包含各种信息。 - 检测时,选择一个
checkpoint,再选择一个数据源,提交任务即可。 - 在检测开始后,可以选择注入一些异常,同时通过算法评价模块来查看效果。
核心概念
Bencmark
一个 Benchmark 是一套完整的微服务系统,为后续的算法开发提供了一些基础的数据:Metric、Log 等。
目前支持 Sock-Shop、Google 的 Online-Boutique、复旦的 Train-Ticket;可以随意扩展。
TestBed
一个 TestBed 是一个运行起来的 Benchmark,通过 K8S 的 Namespace 来实现隔离,用户之间不会互相影响。

Model
我们提供了一套基于 Python 的 SDK,使用 SDK 开发的算法可以被托管至平台,通过平台实现算法的训练和部署。

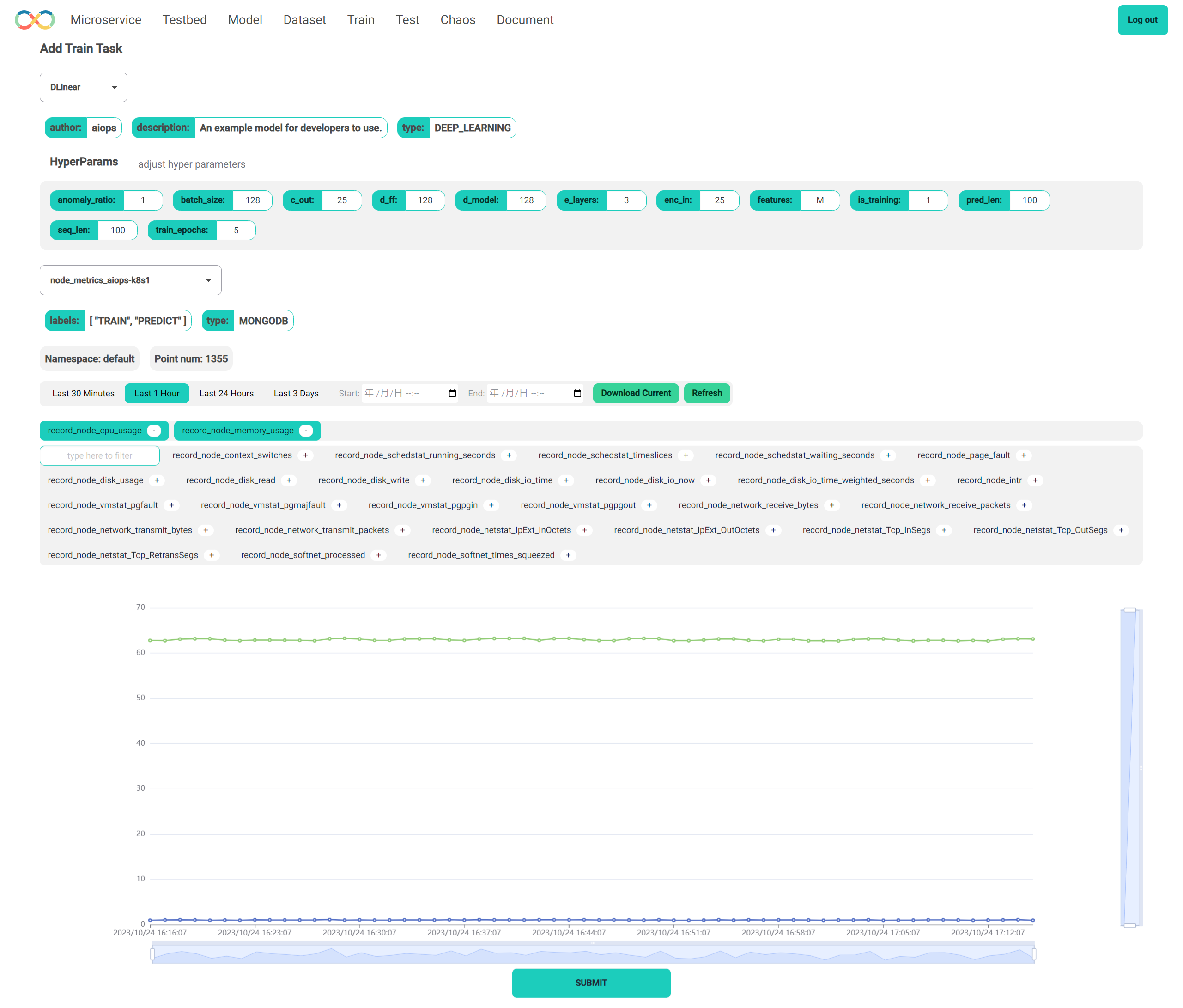
训练
可以选择一个基于 SDK 开发的算法,然后指定一些训练参数,提交训练任务。
训练任务会被封装成一个 K8S 的 Job,训练的产物会被保存在 Redis 中。
检测
如果有一个训练过的算法和一个实时的数据源 (Kafka),就可以提交一个实时的检测任务。
检测任务会被封装成一个 K8S 的 Pod,持续的进行检测;检测的结果也会写入 MongoDB 中保存
评估
在算法运行的时候,我们可以通过 Chaos 模块注入各种各样的异常,然后通过前端来对算法的检测效果进行评估。
比如上一张图,算法检测的就非常准确。同时,借助数据库中的信息,我们还支持计算在一段时间内的 P、R、F1 值来对多个算法进行比较。
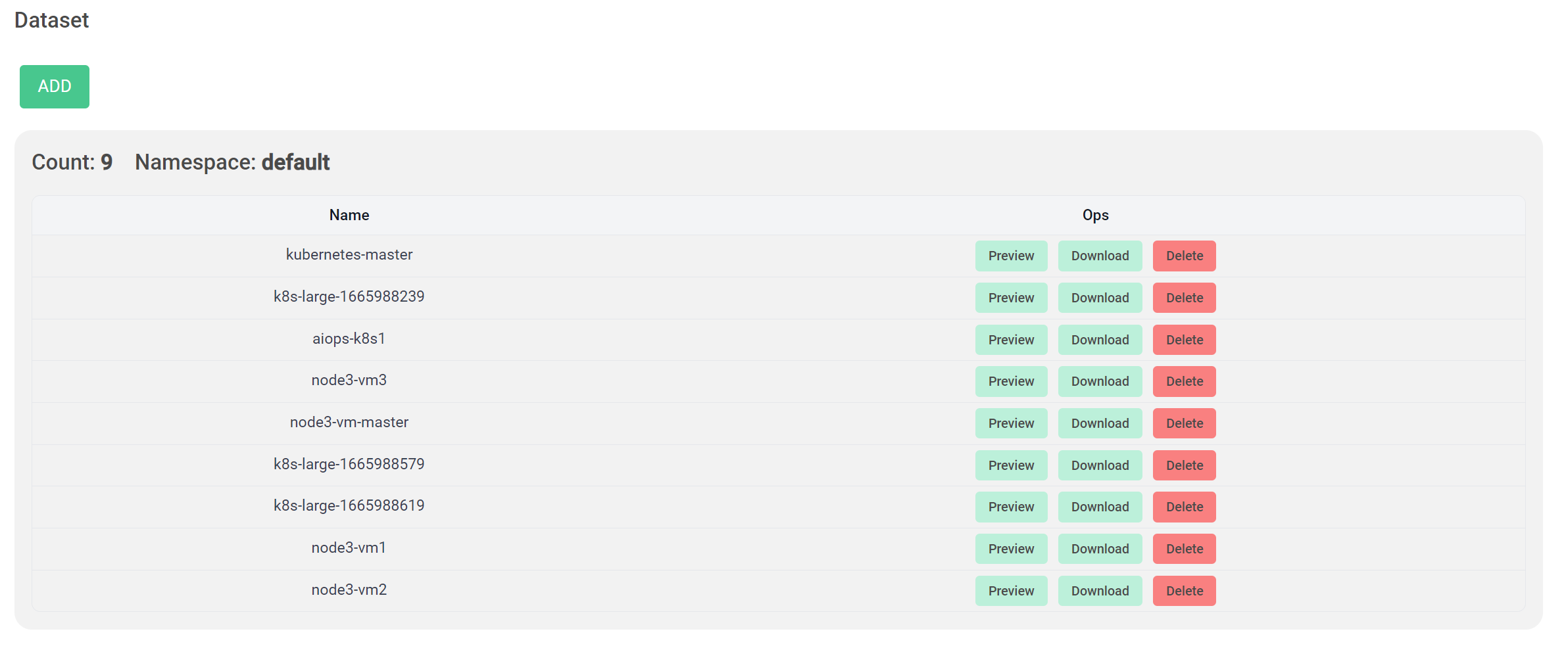
Dataset
当部署了一个 TestBed 之后,平台会自动的将这个 TestBed 所涉及的服务的各种指标收集起来,整合成一个 Dataset。
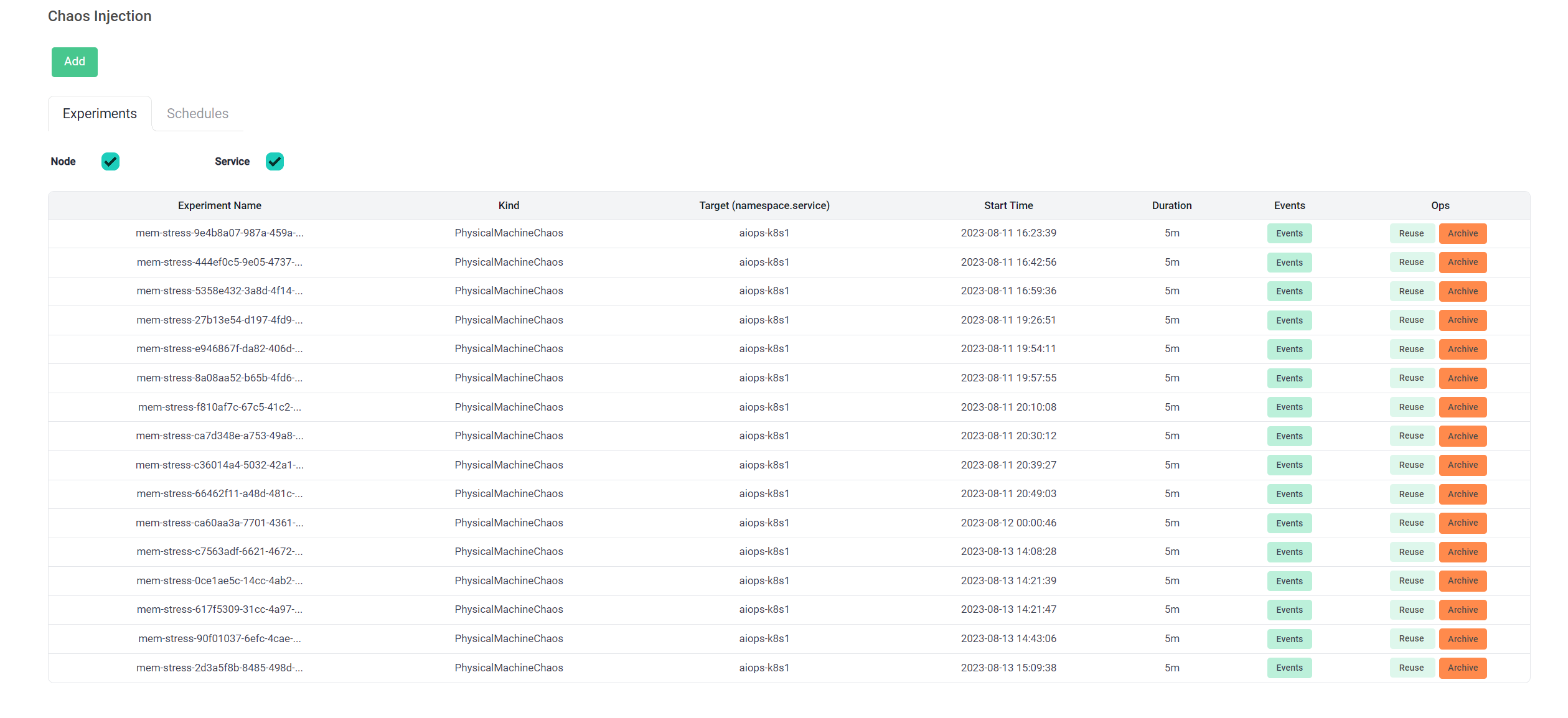
Chaos
异常注入部分,我们对 ChaosMesh 进行了集成、封装和扩展。当注入一个异常之后,这次注入的信息会被写入 MongoDB。
由于底层的基础设施是多用户公用的,因此,对于一般的用户,不支持对节点、网络进行异常注入,这样会导致集群的不稳定。只有我们自己能对这些基础设施进行异常注入。